
Along with the use of target networks, replay memory stands out as one of the most impactful innovations in deep reinforcement learning. Replay memory has been successfully deployed in both value based and policy gradient based reinforcement learning algorithms, to great success. The reasons for this success cut right to the heart of reinforcement learning. In particular, replay memory simultaneously solves two outstanding problems with the field.
First, deep neural networks require that inputs be independent and uncorrelated. In temporal difference learning based methods, or even Monte Carlo type algorithms like REINFORCE, this requirement is instantly violated. Successive time steps in the episode are related through the dynamics of the environment and the action of the agent, and are thus most certainly correlated. In fact, this is precisely what underpins the Markov property of the system. Without the Markov property, we are simply unable to use the mathematics of reinforcement learning.
Now, we do need to mention the fact that REINFORCE definitely works, albeit in a very limited sense. While the agent can learn to navigate simple environments, performance is limited in absolute terms, and the agent tends to overfit its experiences. This is evidenced sharp dropoffs in performance that are often irrecoverable.
Replay memory solves this problem allowing the agent to treat its experiences as a dataset and effectively shuffle it to sample experiences. By sampling historic experience at random, the agent is guaranteeing that the majority of the inputs will be uncorrelated. Naturally, for small memory sizes N, this isn’t strictly true, but it turns out to not be a problem since the memory size grows quickly.
The second problem has to do with sample efficiency, or the lack thereof. Even with Monte Carlo based methods, the agent is only keeping track of a single episode. Worse, temporal difference based methods only make use of two successive time steps. Either way, the end result is that the overwhelming majority of the agent’s experience is discarded.
Obviously, keeping track of everything the agent sees and does solves this problem. Rare experiences that are nonetheless valuable aren’t simply discarded as soon as they are encountered. They can be revisited later, with the hope that the agent learns something generalizable.
Despite the incredible success of replay memory, it’s tempting to ask if we can improve on it in some way. Naturally, the answer is that yes, yes we can.
In particular, we can improve on how we sample the agent’s memories. The default is to simply sample them at random, which works, but leaves much to be desired.
One issue that can be improved upon is that neural networks introduce a sort of aliasing into the problem. Convolutional neural networks in particular perform a sort of feature selection on input images, and then pass these feature encodings to a linear network to solve the Bellman equation. This works enormously well, yet it isn’t without its tradeoffs.
Images that may be completely distinct from a human perspective could very well turn out to be nearly identical to the neural network. It’s not an exaggeration to say that computer vision is nearly alien to us; keying in on features we can’t even recognize. In effect this is a sort of aliasing of the inputs, and the result is that we end up storing experiences that are so similar as to be the same.
Does it really make sense to sample these similar transitions over and over? How much can the agent really learn from this? Wouldn’t the agent learn more from sampling totally distinct experiences?
One solution, off the top of my head, may be to take the end result of the convolution and compare its distance in parameter space to other memories already in our buffer. If it’s too close, then don’t sample it, or perhaps don’t even bother storing it. This is something that may work, but it has some obvious shortcomings. Namely, how close is too close? Not to mention the computational complexity involved with the distance calculations and comaprisons.
The better solution is to introduce the idea of priority. We can assign some sort of priority to our memories, and then sample them according to that priority. A natural candidate for this priority is the temporal difference error. It’s something we have to compute every time we update the neural network, it’s unique to each transition, and it is directly related to the outputs of our neural network.
Just to jog your memory, the TD error has the following form:
$$ \delta_t = r_t + \gamma Q_{target} (S_{t+1}, argmax_a Q(S_{t+1}, a)) – Q(S_t, a_t) $$
It’s worth noting that $ \delta $ can be both positive or negative, and in practice we take the absolute value as we’re only really interested in the magnitude.
So what’s the intuition of this quantity as a measure of priority? In some sense, the difference in the Q functions for successive timesteps is the measure of how surprised the agent is the transition. It’s the distance between the bootstrapped estimate of the current and next state, which shrinks over time as the agent’s estimates for these two parameters converge on their true values.
Just a quick caveat, this only really holds in the case that the rewards from the environment aren’t particularly noisy. If there is significant noise in the reward distribution for the environment, then this delta can end up not converging over time. The authors of the paper address this point in the appendix, though we won’t belabor it here.
With our priority metric defined, we have to address the question of precisely how we’re going to use this to sample our memory. One obvious idea is to simply take the largest priority transitions and sample those at each time steps. We can call this greedy prioritization, and it’s indeed a valid strategy, though it has some serious flaws.
Namely, transitions with a low TD error may never get replayed. In this case, this is actually worse than random uniform sampling. At least with random sampling low priority transitions have some probability of being sampled.
Another flaw, potentially more serious, is that these TD errors shrink slowly over time. This means that the agent is bound to sample the same memories over and over, which leads to overfitting.
Thankfully, we can solve both of these issues with one simplification. We can use a probabilistic sampling, where the probabilities are monotonically dependent on the priority. This idea is called stochastic sampling, and we can use a form that interpolates between purely greedy and purely random sampling.
In particular, we sample a transition according to the following probability:
$$ P(i) = \frac {p_i^{\alpha}} {\sum_{k} p_k^{\alpha}} $$
where the $ p_i $ is the priority of the ith transition.
The parameter $ \alpha $ controls how much prioritization we use, with $ \alpha = 0 $ being uniform random sampling.
Then we’re left with only a single question: how do we determine these priorities?
In the paper, the authors propose two ways. First, we can use proportional prioritization where $ p_i = \left| { \delta_i } \right| + \epsilon $ where this $ \epsilon $ is a small positive constant that deals with the edge case of a transition with zero TD error.
The second possibility is to use a rank based variant, where $ p_i = 1 over {rank(i)} $ where the rank is the rank of the ith transition when the memories are sorted according to $ \left| {\delta} \right| $
It turns out in the paper that both have similar performance, and tend to tradeoff wins in various environments. In fact, in some cases performance may even be worse than the uniform case!
In terms of implementation, we have to use some uncommon data structures.
For the rank based variant, the authors use a max heap data structure. This is an array representation of a max heap binary tree. In a max heap binary tree, the root element is the largest and each leaf is smaller than its parent.
Check out the figures below to get some basic idea of how this works, for a small toy example.
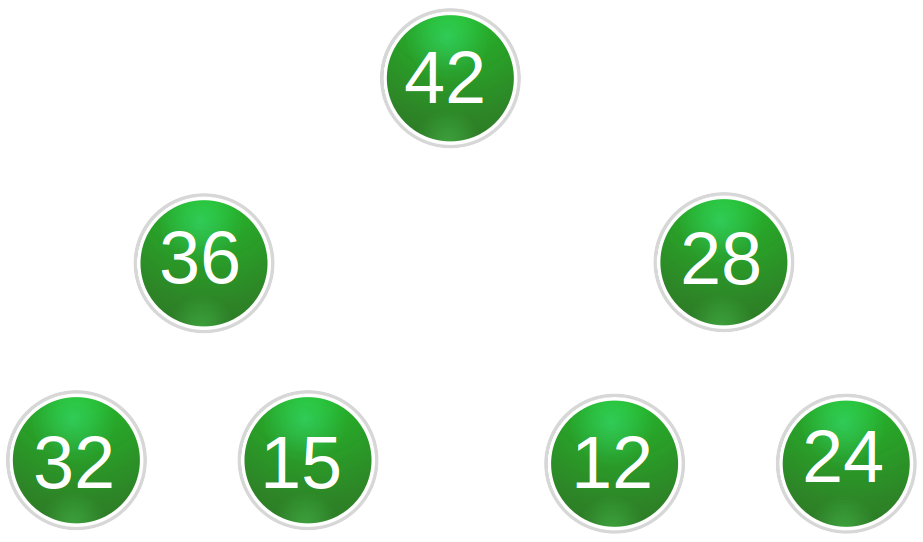

The idea is that if we arrange our entire memory this way, we can sample it quite efficiently. We simply divide up the memory into, say, 32 chunks of equal size. And then we sample from each of those chunks a single number, according to the probabilities given above.
When we get new transitions, we append them to the back of the memory and assign a large priority such that they are virtually guaranteed to be sampled. Every so often we can rebalance our heap, just to make sure things don’t get too far out of whack.
The beauty of this approach is that we can actually precompute our probabilities. We know each time we balance our heap that each transition will go into a spot based on its priority. We’ll automatically know the rank, and therefore the probability distribution. This saves us time from having to compute those probabilities each time we sample a transition. My own testing for the Academy shows an order of magnitude speed up from this approach, and this is affirmed the authors of the paper.
In a future article we will discuss the nuances of the proportional method, which uses the sum tree approach. This is going to be critical, as examining Deep Mind’s code for the Reverb database (upon which their ACME framework depends) uses the proportional scheme over the rank based.
Very good article indeed. Thank you, Phil.
Spelling error on last word in 12th paragraph: comaprisons.
Just a small detail, but I thought I'd mention it.
You can delete this comment once you see it as it doesn't pertain to the actual content of the article.